Insights
What is AWS Glue? Overview and Features
February 17, 2022
AWS Glue is a fully managed extract, transform, and load (ETL) service that makes it simple and cost-effective for customers to categorize their data, clean it, enrich it, and move it reliably between various data stores. It is a serverless data integration service that makes it easy to prepare data for analytics, machine learning, and application development. AWS Glue provides all the capabilities needed for data integration, so you can gain insights and put your data to use in minutes instead of months. With AWS Glue, there is no infrastructure to set up or manage. You pay only for the resources consumed while your jobs are running.
Ever wonder why major big tech companies utilize AWS Glue? In this article, we explain the importance and impact an organization can have once utilizing AWS Glue services. Before we dive deep, let’s answer some common questions about AWS Glue.
What is ETL?
Extract, transform, load (ETL) is the predominant data integration process for loading information from one or more source databases into a target database or data warehouse. Having a well-designed ETL system is essential for a data warehouse to unlock the insights contained within databases. ETL tools must address challenges such as correctly transforming the data between source and target, dealing with a wide variety of data sources, and scaling to handle massive volumes of data.
The 3 Main Components of AWS Glue
- AWS Glue Data catalog – a central repository for your metadata, built to hold information in metadata tables with each table pointing to a single data store.
- Job scheduling system – helps you automate and chain your ETL pipelines. It comes in the form of a flexible scheduler that’s capable of setting up event-based triggers and job execution schedules
- ETL Engine – AWS Glue’s ETL engine is the one component that handles ETL code generation. It automatically provides this in Python or Scala, and then proceeds to even give you the option of customizing the code
Together, these automate much of the undifferentiated heavy lifting involved with discovering, categorizing, cleaning, enriching, and moving data, so you can spend more time analyzing your data.
Main Features of AWS Glue
Data Discovery
The AWS Glue Data Catalog is your persistent metadata store for all your data assets, regardless of where they are located. The Data Catalog contains table definitions, job definitions, schemas, and other control information to help you manage your AWS Glue environment. It automatically computes to make queries against your data efficient and cost-effective. It also maintains a comprehensive schema version history so you can understand how your data has changed over time.
Data Transformation
AWS Glue jobs can be triggered on a schedule, on-demand, or based on an event. You can start multiple jobs in parallel or specify dependencies across jobs to build complex ETL pipelines. AWS Glue will handle all inter-job dependencies, filter bad data, and retry jobs if they fail. All logs and notifications are pushed so you can monitor and get alerts from a central service.
Data Replication
AWS Glue Elastic Views enables you to create views over data stored in multiple types of AWS data and materialize the views in a target data store of your choice. You can use AWS Glue Elastic Views to create materialized views by writing queries in PartiQL. PartiQL is an open-source SQL-compatible query language that you can use to query and manipulate data, regardless of whether the data has a tabular or a flexible, document-like structure.
Data Preparation
AWS Glue helps clean and prepare your data for analysis without becoming a machine learning expert. For instance, its ‘FindMatches’ feature finds records that are imperfect matches of each other. The system will learn your criteria for calling a pair of records a “match” and will build an ETL job that you can use to find duplicate records within a database or match records across two databases.
How AWS Glue Works
You are now familiar with what AWS Glue is, the main components, and the features it brings to your enterprise. But how should you use it? Surprisingly, creating and running an ETL job is just a matter of a few clicks in the AWS Management Console.
All you need to do is point AWS Glue to your data stored on AWS, and AWS Glue will discover your data and store the associated metadata (e.g., table definition and schema) in the AWS Glue Data Catalog. Once cataloged, your data is immediately searchable, queryable, and available for ETL.
Here’s how it works:
- Define crawlers to scan data coming into S3 and populate the metadata catalog. You can schedule this scanning at a set frequency or trigger at every event
- Define the ETL pipeline and AWS Glue with generating the ETL code on Python
- Once the ETL job is set up, AWS Glue manages its running on a Spark cluster infrastructure, and you are charged only when the job runs
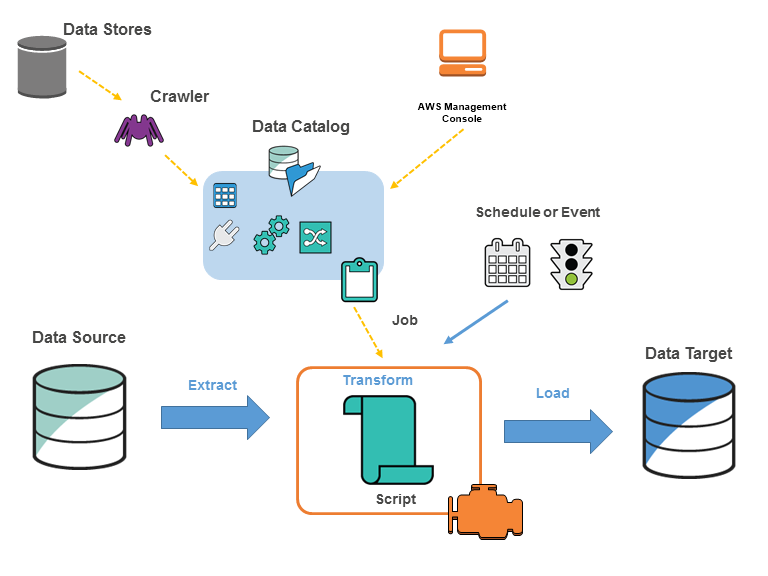
Figure 1: Architecture of an AWS Glue environment
The AWS Glue catalog lives outside your data processing engines and keeps the metadata decoupled. So different processing engines can simultaneously query the metadata for their different individual use cases. The metadata can be exposed with an API layer using API Gateway and route all catalog queries through it.
Why Organizations Should use AWS Glue
AWS Glue is used to organize, cleanse, validate, and format data for storage in a data warehouse or data lake. It’s popular amongst organizations that are trying to put an enterprise-class data warehouse. Organizations can benefit from the fact that AWS Glue seamlessly facilitates the movement of data from various sources. The process is simple and straightforward. You can transform and move AWS Cloud data into your data store.
AWS Glue simplifies many tasks when you are building a data warehouse or data lake:
- Discovers and catalogs metadata about your data stores into a central catalog. You can process semi-structured data, such as clickstream or process logs.
- Populates the AWS Glue Data Catalog with table definitions from scheduled crawler programs. Crawlers call classifier logic to infer the schema, format, and data types of your data. This metadata is stored as tables in the AWS Glue Data Catalog and used in the authoring process of your ETL jobs.
- Generates ETL scripts to transform, flatten, and enrich your data from source to target.
- Detects schema changes and adapts based on your preferences.
- Triggers your ETL jobs based on a schedule or event. You can initiate jobs automatically to move your data into your data warehouse or data lake. Triggers can be used to create a dependency flow between jobs.
- Gathers runtime metrics to monitor the activities of your data warehouse or data lake.
- Handles errors and retries automatically.
- Scales resources, as needed, to run your jobs.
How Zelusit Can Help
Zelusit is an Advanced Consultant Partner for AWS that specializes in delivering fast analytics on the Cloud. We offer services around Data Estate Modernization, AI (Artificial Intelligence) & Analytics, Governance, and Managed Services. Through best-in-class methodologies, we have helped organization bolster their growth and speed to business impact. Our clients have been seen to increase employee efficiency, enhance customer experience, a dramatic increase in time and resource-saving through implementing AWS solutions. Our team of experts have moved clients away from pricey license-based tools to pay-as-you-go systems which has not only reduced their bottom line but increased the performance of their operations, by leveraging scalable Apache spark engine and data frames. We develop ETL frameworks that act as a set of reusable python libraries which enable standardizing job creation, audit logging, except handles, etc.
By using Amazon Athena, organizations can set up data catalogues, outlining all sources, and target datastores to leverage glue development and enable self-explorations. Our experts will guide you through a seamless process of amalgamating AWS platform services with our robust solutions, ensuring your pertinent data challenges are met head-on and successfully overcome.
Our extensive experience with Cloud solution makes us the ideal partner to help you in democratizing your data to make it readily available to end-users. We understand that data-driven decision-making is key at various levels in your organization, and by enabling users to access and analyze data through a user-friendly interface, you can make the most of data across your organization.


