GCP Migration and Data Lake Implementation
Our client wanted to migrate their Hadoop-based on-premises data lake solution to Google Cloud.
availability and uptime
managed Google Cloud environment
capacity limitations
Background and Problem
A large Canadian organization wanted to migrate their Hadoop-based on-premise data lake solution to the Cloud. The re-platforming needed to be completed within a strict timeline, as the client’s existing technical solution was scheduled to run out of support soon. The client had already decided to move to the Cloud and had selected Google Cloud Platform as their partner of choice.
The client wanted the migration to be as much lift-and-shift as possible, as some of their systems had been developed recently, and Zelusit was brought in to plan and perform the migration.
Client’s Original Solution
The client’s original solution was on-premise and consisted of two Hadoop clusters. The first was a Production cluster, which was primarily used to collect data from all sources and also distribute data to internal and external downstream systems. Unlike a typical Data Lake, which is mostly used for reporting and analytics, the client’s Data Lake was also providing data to operational systems.
The second cluster was a Disaster Recovery (DR) cluster, where data was replicated from the Production cluster to the DR cluster, and this replica of production data was used for reporting and analytics.
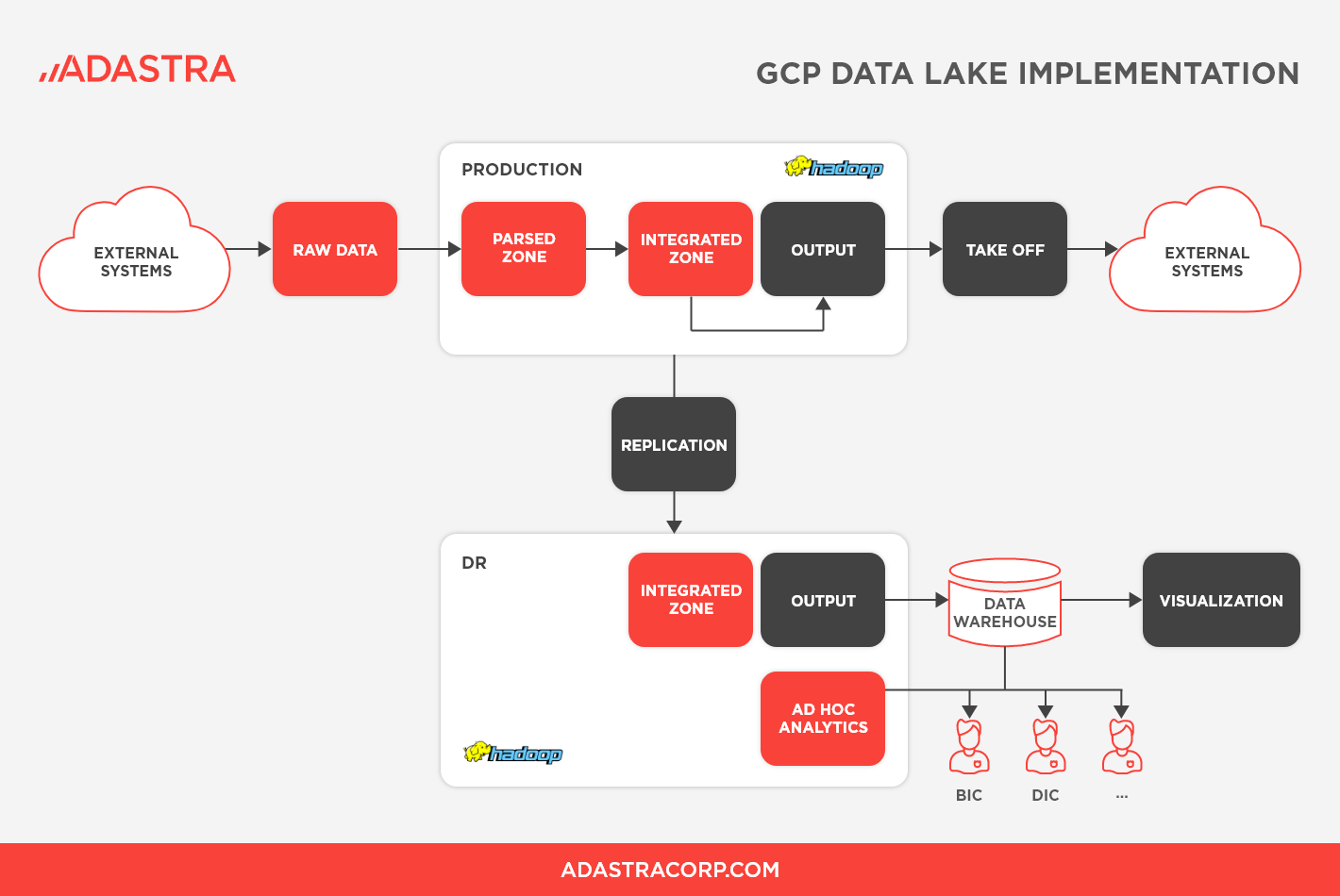
Figure 1: GCP Data Lake Implementation
Zelusit’s Approach to GCP Data Lake Implementation
Zelusit was involved in the migration planning from the very beginning, and our consultants implemented the migration process end-to-end. Since the client’s applications were relatively recent, they wanted a largely lift-and-shift migration, with as little re-coding as possible. Zelusit migrated all the applications with very limited changes that were required to make the system operational on the new platform.
The first three months of the project were dedicated to planning and executing proofs of concept regarding compatibility of the solution with Google cloud technologies. Following that, the team spent another three months in creating a detailed architecture design for the target solution and detailed migration plan. Next, the standing up of the environment was completed and installation of applications and the initial data copy was done.
Once the production environment in GCP was up, we started a parallel run, where all data sources originally pointing to the on-prem production environment were now also pointed to the GCP environment. During this time, the original production environment was still being used for operations, and all processes that were running on-prem were also run in parallel on GCP. Any issues that emerged on the GCP environment were fixed, and the outputs from all processes were compared and validated to ensure that the same results were obtained in both on-prem and GCP. The complete switch over happened and the new environment went live in less than a year after the migration effort was started.
- GCP Migration
As part of the lift-and-shift of the data lake, the individual elements in the new architecture were replaced by Google Cloud Platform components of identical or similar functionality. The edge nodes which connected the Hadoop cluster to the outside world in the on-prem solution were replaced by Google Compute instances (or virtual servers dedicated to communication outside GCP).
One significant advantage of the migrated solution was the separation of compute and storage in the GCP environment. In the on-premise Hadoop cluster, the nodes were used both for computational power and storage, but in the cloud environment, Google Cloud Storage (GCS) was used for storage, and Dataproc clusters provided compute capabilities. So, instead, of having a compact cluster (as in the Hadoop solution), the GCP Production cluster was split into several Dataproc clusters used for various tasks, like data integration, production support, etc.
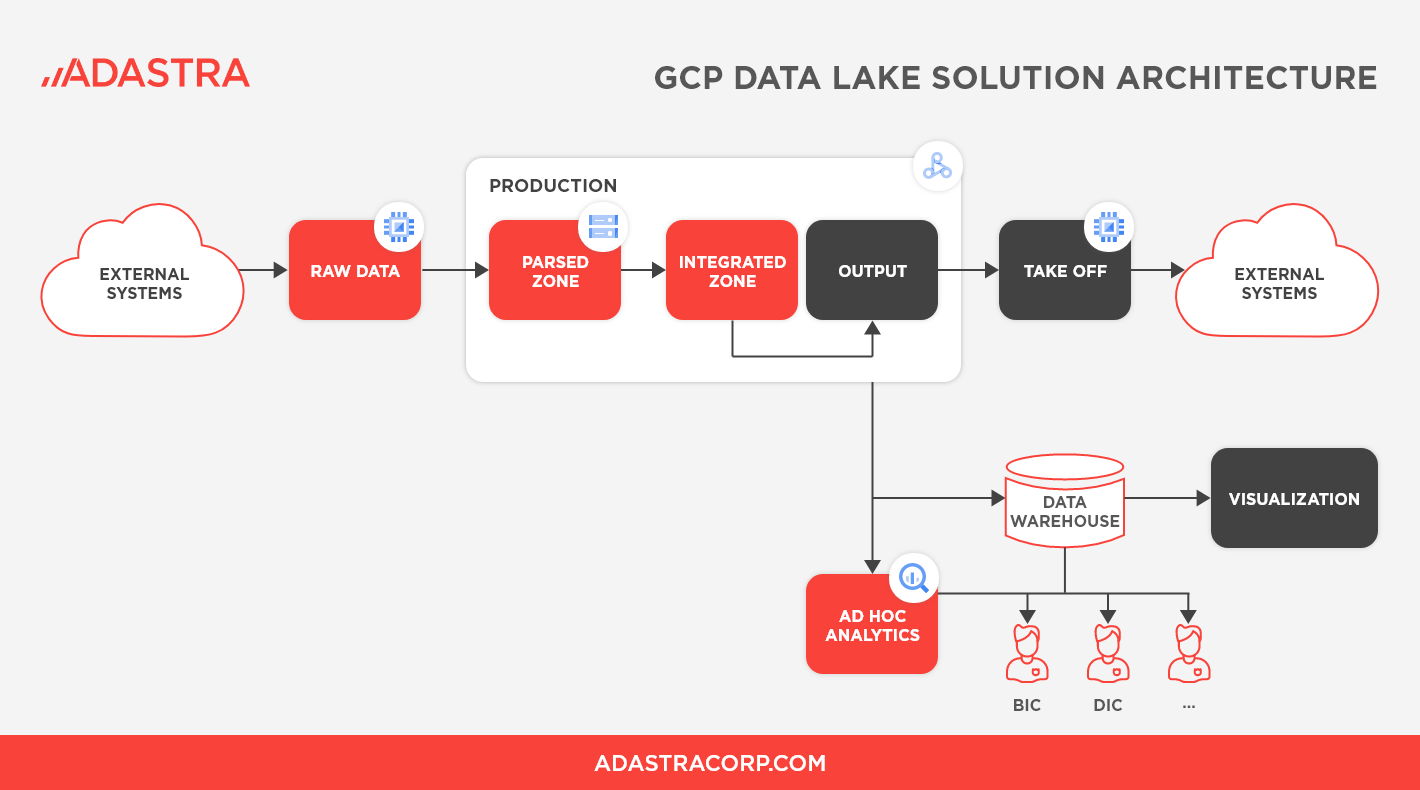
Figure 2: GCP Data Lake Solution Architecture
The data in the new architecture was not only stored in Google Cloud storage but also copied and made accessible to BigQuery for analytical processes. Another major difference was that unlike in the on-premise solution, there was no real physical Disaster Recovery (DR) cluster in the cloud. DR capabilities are natively supported by GCP, and the data is duplicated across data centers spread across multiple regions, eliminating the need for a separate DR cluster. This means that the Production cluster will be highly available in case one Data Centre is not accessible or even in case of a major regional disaster. In the client’s original solution, the analytical team was accessing DR data, but the new solution allowed them to access production data directly using BigQuery for analytics.
Impact
- Limitless scalability
- Fully managed cloud environment
- Separation of compute and storage
- GCP tool stack
With the client’s existing on-premise solution scheduled to run out of support soon, the client had no option but to migrate. One big advantage of moving to the Cloud was that the underlying technology was fully managed by the cloud provider, and the client’s team no longer needed to maintain Hadoop clusters. Unlike on-premise environments, the cloud also offers limitless flexibility, and the client can now scale up their solution and data easily, without tedious capacity and provisioning planning.
Since this was a lift-and-shift migration, the client can continue to use the same applications, with the additional flexibility of connecting new applications to the solution in the future. They will also be able to seamlessly leverage the existing and emerging tools and technologies available in GCP.
The separation of compute and storage, too, has some added benefits. For one, other solutions can now easily connect with the storage without any issues. It also allows for more granularity in computing and access to stored data and helps in further increasing availability and scalability.
Looking for help with your solution migration? Zelusit’s expertise spans across cloud platforms and our team can help you efficiently plan and implement migrations. Contact us to learn more.


