Insights
Leveraging The Power of Intelligent Search for Question-Answering Systems
January 31, 2022
Exploring data, searching unstructured sources, and finding direct answers to company-specific questions in internal systems are vital but cumbersome tasks for many businesses. When a company stores thousands of documents linked to customers, employees, catalogs, and other internal text data, designing and deploying a system to retrieve relevant information can pose a significant challenge. Moreover, it is often unclear which data source contains relevant material related to a user query, leading to even more complexity. Traditional search strategies for retrieving a subset of text in a collection of documents are only effective when the texts are comparable in terms of word frequencies. However, when words in a query have different importance and diverse meanings based on context, the traditional methods can fail to return relevant information. Therefore, there has been an increased need for businesses to invest in custom intelligent search systems backed by Artificial Intelligence (AI) and Machine learning (ML) to analyze the context of user queries and an internal text corpus.
Natural language processing (NLP) is a branch of linguistics and Machine Learning that studies how intelligent systems interact with human language, particularly how to design computers to process and analyze massive volumes of natural language data with the aim of understanding the contents of documents [1]. A text mining system using NLP may extract text features, discover industry-specific knowledge from text, and interpret the text in a meaningful way. Today, NLP plays a critical key role in building Question-Answering machines and Intelligent Search systems.
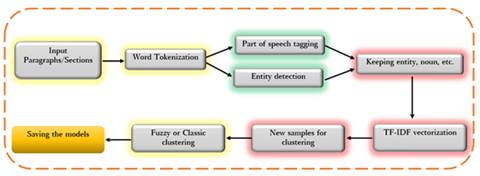
Figure 1: Process of feature extraction and creating a new dataset for clustering
Finding a solution to directly answer a question among thousands of documents requires two key processes. The first step involves narrowing down the documents, sections, or paragraphs to a smaller subset that is most likely to be related to the user’s query. Following this, a Q/A algorithm can compare the user query to the selected texts and determine the proper answer among them. Once Q/A or search systems are deployed, MLOps best practices can be employed to continuously update search algorithms to consider increasing volumes of underlying company data.
Filtering Documents from a Large Set of Text Data
In order to speed up the performance of Question-Answering systems, obtaining a small set of most relevant documents to search from the source of all documents is necessary. Here, we review two different methods that apply ML algorithms to solve this problem.
A) Document Clustering and Query Classification
When documents have not been previously classified or tagged with search categories, we can apply an unsupervised clustering method to group similar documents into respective groups or clusters. The first step to applying clustering on the text data is to shrink each document into several sections or paragraphs and index them. Secondly, we can leverage NLP tools to extract valuable features from the smaller text sections. Figure 1 illustrates the process of feature extraction and creation of a new dataset that can be used as an input to a clustering algorithm. As shown in this figure, the idea behind this process is to preserve entities, nouns, and verbs, as well as to remove stop words and insignificant verbs from the text. The cleaned text can then be vectorized, or converted to its numerical form, through Term Frequency – Inverse Document Frequency (TF-IDF) vectorization. The new numerical samples can then be clustered by a classic or fuzzy clustering algorithm, and the resulting models may be saved for later use in the runtime. Depending on the number of data features and their hidden categories, the number of clusters can be optimized. For example, a heuristic technique like the Elbow method can be used to optimize the number of clusters produced.
The saved clustering models can then be used for classifying the query during runtime, where the query is assigned to the most relevant cluster. As a result, the texts inside the cluster are selected among a large set of texts, in turn improving the speed and performance of the final search and question-answering algorithm (Figure 2).
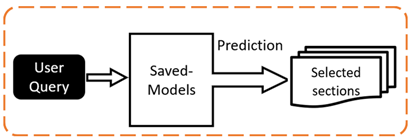
Figure 2: Classifying the user query by a pre-saved clustering model
B) Keyword Extraction
Clustering may not always be the optimal solution when the search criteria are predominantly dependent on the keywords of the text while the concept and meaning of those words are less relevant. Keyword extraction is the process of extracting the most frequently used and noteworthy words from a document automatically. ML techniques can be used to effectively extract keywords from a text corpus and allow us to identify the most relevant documents related to our search query. As seen in Figure 3, we can take advantage of Deep Learning and pre-trained transformers like keyBERT to detect the most significant words from an initial input query. In addition, we can add or remove additional keywords as well as ignore certain words in the search. Additional levels of Natural Language Processing may be utilized to identify synonyms/hyponyms of the keywords. Finally, we can search only the extracted keywords or keyphrases from the entire set of documents to find the most related sections.
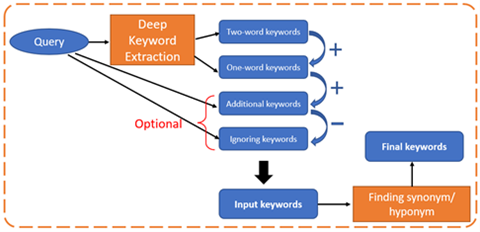
Figure 3: Extracting keywords and keyphrases
Question-Answering
When a subset of all documents is selected as the closest result for the user’s query, an answering machine is expected to comprehend the language’s structure, have semantic knowledge of the context and questions, and identify the most appropriate response phrase. Pre-trained transformers like BERT, GPT-2, GPT-3, T5, etc., which are models that have been pre-trained on very large text sets, have demonstrated to be incredibly successful at the task of question-answering. However, these transformers have their own limitations. GPT-3, for instance, allows us to choose from 4 different models (Ada, Davinci, Curie, and Babbage) of differing costs and performance levels. In addition, the number of documents and quantity of tokens that a question may be searched on is limited. Apart from these restrictions, GPT-3 models have been the most accurate among the available transformers so far and are the current gold standard for various NLP tasks. In contrast, the popular BERT transformer, with a faster version called DistilBERT is completely free to use. However, the number of tokens is also restricted for BERT, a challenge that must be addressed prior to using any of these transformers.
Figure 4 demonstrates a simplified illustration of the Q/A and answer-sorting process based on the similarity of the potential answer to the user’s search query.
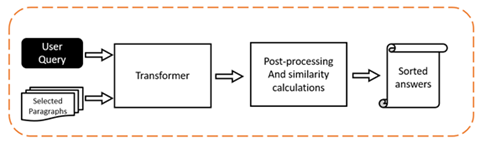
Figure 4: Q/A process and sorting the answers
Regardless of what transformer we employ for the Q/A process, there is always a trade-off between speed and accuracy. The volume of text we send to a transformer, the method we apply for retrieving the most-related documents or sections, and any other NLP algorithms necessary for processing, can all affect both accuracy and runtime.
Continuously Updating Search Systems with New Documents
Company data is continuously growing, and with that comes a need to regularly update and retrain any deployed intelligent search systems to consider all available data. MLOps best practices such as continuous monitoring and CI/CD can aid in triggering automated re-retraining and re-deployment pipelines to ensure users are searching for the most up-to-date company data.
Why Zelusit
Zelusit transforms businesses into digital leaders. For the past 20 years, Zelusit has been helping global organizations accelerate innovation, improve operational excellence, and create unforgettable customer experiences, all with the power of their data. By providing cutting-edge Artificial Intelligence, Big Data, Cloud, Digital, and Governance services and solutions, Zelusit helps enterprises leverage data they can control and trust, connecting them to their customers – and their customers to the world.
With continuous advancements in Artificial Intelligence and Machine Learning, Zelusit invests in ongoing learning to stay abreast of recent developments, including certifications and research partnerships with academic institutions and government supercluster programs. Zelusit focuses on providing practical applications that will give your business a competitive edge. From simpler regression models leveraging structured data to more complex models leveraging various types of structured and unstructured data, our team of highly qualified data scientists can build models that fit your specific business needs and data sets. Let Zelusit help your company achieve data quality excellence.


