Insights
Unstructured vs Structured Data: What is Unstructured Data + Unlocking Insights
February 20, 2022
It is well documented that organizations are generating more data than ever before. Increasingly, the data that is gaining in both volume and veracity is described as unstructured. Developing analytics and insights from this data is underdeveloped resulting in organizations missing out on valuable information to create value. To leverage unstructured data, it must first be processed and converted into a useable, structured form for downstream analytics.
What is Unstructured Data?
Data structure can fall under three categories: structured, semi-structured, or unstructured (Table 1). Structured data has pre-defined data models that fit a tabular format, with relationships between rows and columns. This type of data is found in traditional relational databases or Excel files and is the most used source for data analysis given its clean structure and ease of use.
Unstructured data, however, lacks a pre-defined data model and can be found in numerous formats, the most common being text. Some data also falls into the semi-structured category, implying there is still no formal data model though the data has been tagged or organized in a way that makes it easier to use than completely unstructured data.
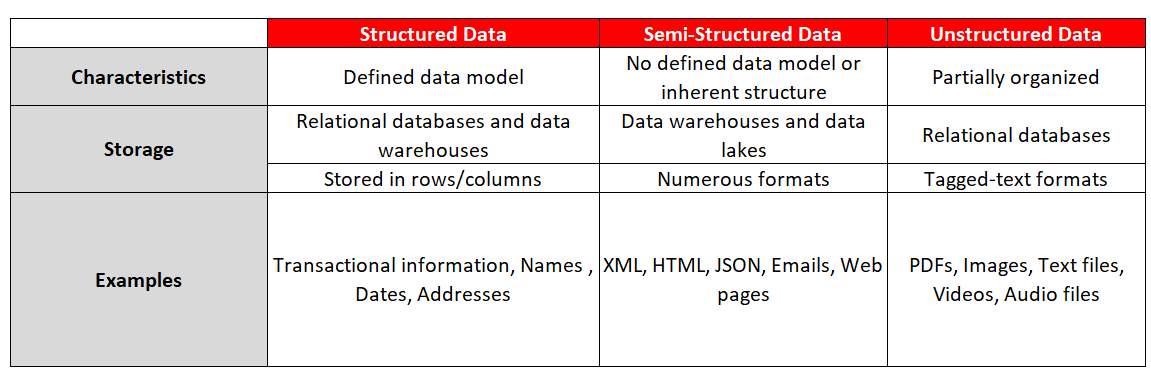
Table 1: Types of Data Structures
As the volume of unstructured data continues to grow at an increasingly high rate, methods, and technologies to store, process, and analyze this data are continuously evolving. Here, we describe the processing, transformation, and analysis of the most common unstructured data sources: text and images.
Text Processing
Text processing and analytics involves the automated analysis of electronic text, leveraging a variety of Natural Language Processing (NLP) and Machine Learning (ML) techniques to extract valuable insights. Text data is typically pre-processed and then vectorized, or converted into its numerical representation, so it can then be used by ML models or other analytics techniques that rely on structured numeric data as input. While there are many potential pre-processing methods that can be performed depending on the use case, some common steps include:
Lowercasing of all words. This allows machines to treat identical words equally, regardless of their capitalization.
Punctuation and stop word removal. Stop words are commonly occurring words in text that do not provide meaningful information. Both punctuation and stop words are removed in order to reduce noise and filter out unnecessary features from the dataset.
Stemming and Lemmatization. These are processes to convert words into their root form. For example, “playing” is converted to “play”. This process allows words with the same meaning to be identically represented.
Removal of rare and frequent words. This process is similar to removal of stop words but is domain-specific. Words that occur very rarely or frequently across documents tends to be less meaningful for analysis and can be removed.
Additional steps such as Named Entity Recognition (NER) and Part-of-Speech Tagging (POS) tagging are often performed to provide meaning to data, such as whether a word is a noun or adjective, and what types of entities are described in the text. To further prepare text data for downstream analytics and ML tasks, it must be converted to a numerical representation. This process can be done through simple frequency-based methods which consider words counts within and across documents, to more sophisticated methods that also take into account the context and semantics behind text. Common methods include Word2Vec, TF-IDF, and Glove, as well as transformer-based methods such as BERT and GPT-3.
Processed and vectorized text data can be used for a variety of meaningful business tasks, such as development of intelligent Chatbots, classification of social media posts, identification of phishing or other digital attacks, among many others.
Image Processing
Similar to text processing, image processing involves the automatic analysis of digital image data. Digital images are processed and analyzed as pixel values, which represent image elements such as grey levels, colours, heights, and opacities.
To prepare imaging data for analytics tasks, common processing steps include:
Resizing of all images. Images captured vary in size. A base size should be established to feed images into AI algorithms.
Noise removal. Eliminate unwanted signals from imaging data while retaining key features. A common technique is Gaussian blur, a mathematical function which smooths out uneven pixels and aids in removing extreme outliers from images.
Grayscale conversion. This step converts coloured images to black and white, reducing computational complexity.
Normalization. Re-scaling data to pre-defined pixel ranges is necessary for many ML algorithms.
Segmentation. This step involves partitioning an image into multiple segments. This is often useful for object detection and contour recognition tasks.
Data augmentation. If data is limited, various augmentation techniques such as horizontal/vertical shifting or flipping, rotation, brightness, and zoom manipulations can be performed.
While there are numerous image analytics tasks that can be carried out after initial cleaning and processing, two common tasks are object detection and optical character recognition.
Object detection is a type of computer vision task which involves recognizing the location of objects in digital images or videos. Pre-trained deep learning algorithms such as YOLO and SSD have shown high performance, both in terms of speed and accuracy. These models allow for single-pass object detection, meaning each object in an image can be detected and outlined with a bounding box in a single pass through the neural network.
Optical character recognition is the process of automatically extracting text from scanned documents or images. This process eliminates the need for manual data entry and can support downstream NLP tasks such as intelligent search or document summarization. Several open-source OCR engines and libraries exist today, including Tesseract, GOCR, and Kraken.
Image processing and analytics can aid in unlocking valuable insights from images, such as anomaly detection on manufacturing lines, tumour detection and classification in medical scans, facial recognition in security systems, and many more.
Challenges and Conclusion
While unstructured data can hold a wealth of information and insights, it is significantly more challenging to process and analyze not only due to its complexity, but also its increasing size. AI and ML technologies are continuously improving to handle a wide range of unstructured data processing and analytics tasks, as outlined above. However, as the volume of an organization’s unstructured data continues to increase, traditional storage methods often fall short. This increasing volume can also become a blocker to analytics applications that require continuous training on new data. Leveraging cloud technologies that allow for dynamic scaling of storage systems, as well as following MLOps best practices for data integration and model-retraining, both assist in allowing companies to extract insights reliably and continuously from their unstructured data sources.
Why Zelusit
Zelusit transforms businesses into digital leaders. For the past 20 years, Zelusit has been helping global organizations accelerate innovation, improve operational excellence, and create unforgettable customer experiences, all with the power of their data. By providing cutting-edge Artificial Intelligence, Big Data, Cloud, Digital, and Governance services and solutions, Zelusit helps enterprises leverage data they can control and trust, connecting them to their customers – and their customers to the world.
With continuous advancements in Artificial Intelligence and Machine Learning, Zelusit invests in ongoing learning to stay abreast of recent developments, including certifications and research partnerships with academic institutions and government supercluster programs. Zelusit focuses on providing practical applications that will give your business a competitive edge. From simpler regression models leveraging structured data to more complex models leveraging various types of structured and unstructured data, our team of highly qualified data scientists can build models that fit your specific business needs and data sets. Let Zelusit help your company achieve data quality excellence.


